Automatically assemble a desired dataset and navigate through a large number of resulting datasets

Imagine you are a school counselor in Chicago, to help parents and students choose which schools to go to, you want to find a table that contains information about every public school in Chicago, including the school name, its curriculum/degree type (ex: IB, General Education etc), and its latest rating based on Chicago’s School Quality Rating Policy (SQRP).
Prior to constructing a table, you may have a general idea of its desired format. For instance, the following sample table may serve as a reference point to guide the construction of a similar table.
| School | Type | Rating |
|---|---|---|
| Ogden International High School | IB | Level 1 |
| Hyde Park High School | General Education | Level 2 |
| … | … | … |
Constructing a desired table can be a laborious task. One can gather information through Chicago Public Schools (CPS) website that provides information for each school in Chicago and allows you to search the schools. However, manually going through every school to gather the information you need is time-consuming. It’s possible to write a script to crawl data, but you’ll need to know how to write the script and where to find the information you want, which also takes a lot of time.
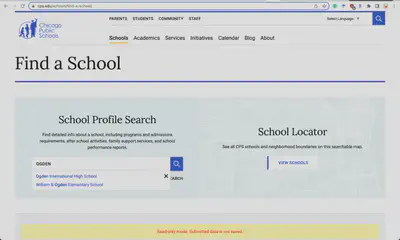
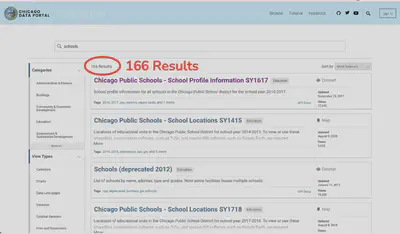
If you are more data savvy, you might heard of Chicago releases many datasets about the city in various domains, such as education. Through the open data portal, you may search for datasets related to “schools”, but it turns out that there are more than hundred datasets and you still have to go through each of them to see if the dataset has everything you need. If it doesn’t, you will have to combine datasets, making the process even harder. And it turns out in our case no single dataset has all the information we need.
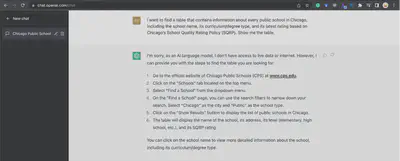
You can also ask ChatGPT, by copy-pasting our problem and asking it to generate a table. Unfortunately it cannot give you the full table based on real-time data sources. The solution it recommended is exactly what we proposed in our first solution.
As we can see, the aforementioned approaches have many drawbacks. First of all, manual Search is time consuming, and we may need to combine datasets without knowing any join information. Additionally, LLMs cannot give you the exact table.
So given large repositories of data which is often noisy and have no precise join information, how do we help users assemble a dataset when they have an example table in mind? Additionally, if there are multiple datasets that fit the user’s example table, how do we navigate the user to the right dataset?